Chủ đề scrape facebook ads library: Scrape Facebook Ads Library là một cách tuyệt vời để thu thập và phân tích dữ liệu quảng cáo. Bài viết này sẽ hướng dẫn bạn từng bước từ cài đặt công cụ đến việc xử lý dữ liệu, giúp bạn tối ưu hóa chiến dịch quảng cáo và đạt được kết quả mong muốn.
Mục lục
- Hướng dẫn scrape Facebook Ads Library
- 1. Giới thiệu về Facebook Ads Library
- 2. Tại sao nên scrape Facebook Ads Library
- 3. Các công cụ hỗ trợ scrape dữ liệu
- 4. Hướng dẫn cài đặt và thiết lập công cụ
- 5. Các bước tiến hành scrape dữ liệu
- 6. Xử lý và lưu trữ dữ liệu
- 7. Các lưu ý quan trọng khi scrape dữ liệu
- 8. Các ví dụ cụ thể về mã nguồn scrape dữ liệu
- 9. Tổng kết và khuyến nghị
- YOUTUBE:
Hướng dẫn scrape Facebook Ads Library
Facebook Ads Library là một công cụ mạnh mẽ cho phép bạn tìm kiếm và khám phá các quảng cáo đang chạy trên nền tảng Facebook. Việc scrape dữ liệu từ Facebook Ads Library có thể giúp bạn phân tích và tối ưu hóa chiến dịch quảng cáo của mình. Dưới đây là các bước chi tiết để thực hiện việc này.
Bước 1: Cài đặt công cụ hỗ trợ
Đầu tiên, bạn cần cài đặt các công cụ hỗ trợ cần thiết để scrape dữ liệu từ Facebook Ads Library. Các công cụ phổ biến bao gồm:
- Python: Ngôn ngữ lập trình mạnh mẽ và linh hoạt cho việc xử lý dữ liệu.
- BeautifulSoup: Thư viện Python dùng để phân tích cú pháp HTML và XML.
- Selenium: Công cụ tự động hóa trình duyệt web để tương tác với các trang web.
Bước 2: Thiết lập môi trường làm việc
Sau khi cài đặt các công cụ, bạn cần thiết lập môi trường làm việc cho việc scrape dữ liệu. Thực hiện các bước sau:
- Cài đặt Python và các thư viện cần thiết bằng lệnh:
- Thiết lập trình điều khiển cho Selenium, ví dụ với ChromeDriver:
pip install beautifulsoup4 seleniumwebdriver.Chrome(executable_path='path_to_chromedriver')Bước 3: Tiến hành scrape dữ liệu
Để scrape dữ liệu từ Facebook Ads Library, bạn cần viết mã nguồn để tự động hóa việc lấy dữ liệu. Dưới đây là một ví dụ đơn giản bằng Python:
from selenium import webdriver
from bs4 import BeautifulSoup
# Khởi động trình duyệt
driver = webdriver.Chrome(executable_path='path_to_chromedriver')
# Truy cập Facebook Ads Library
driver.get('https://www.facebook.com/ads/library')
# Lấy nội dung trang
content = driver.page_source
soup = BeautifulSoup(content, 'html.parser')
# Phân tích và lấy dữ liệu cần thiết
ads = soup.find_all('div', {'class': 'ad-container'})
for ad in ads:
print(ad.text)
# Đóng trình duyệt
driver.quit()Bước 4: Phân tích và lưu trữ dữ liệu
Sau khi scrape được dữ liệu, bạn có thể phân tích và lưu trữ chúng theo cách mình muốn. Bạn có thể sử dụng các công cụ như Pandas để xử lý dữ liệu hoặc lưu trữ vào các định dạng như CSV, JSON.
Lưu ý khi scrape dữ liệu
- Đảm bảo tuân thủ các điều khoản dịch vụ của Facebook khi scrape dữ liệu.
- Tránh làm quá tải máy chủ bằng cách giới hạn số lượng yêu cầu trong một khoảng thời gian nhất định.
- Sử dụng các phương pháp scrape dữ liệu một cách có trách nhiệm và hợp pháp.
Hy vọng hướng dẫn này sẽ giúp bạn hiểu rõ hơn về cách scrape dữ liệu từ Facebook Ads Library và tận dụng chúng để nâng cao hiệu quả quảng cáo của mình.

.png)
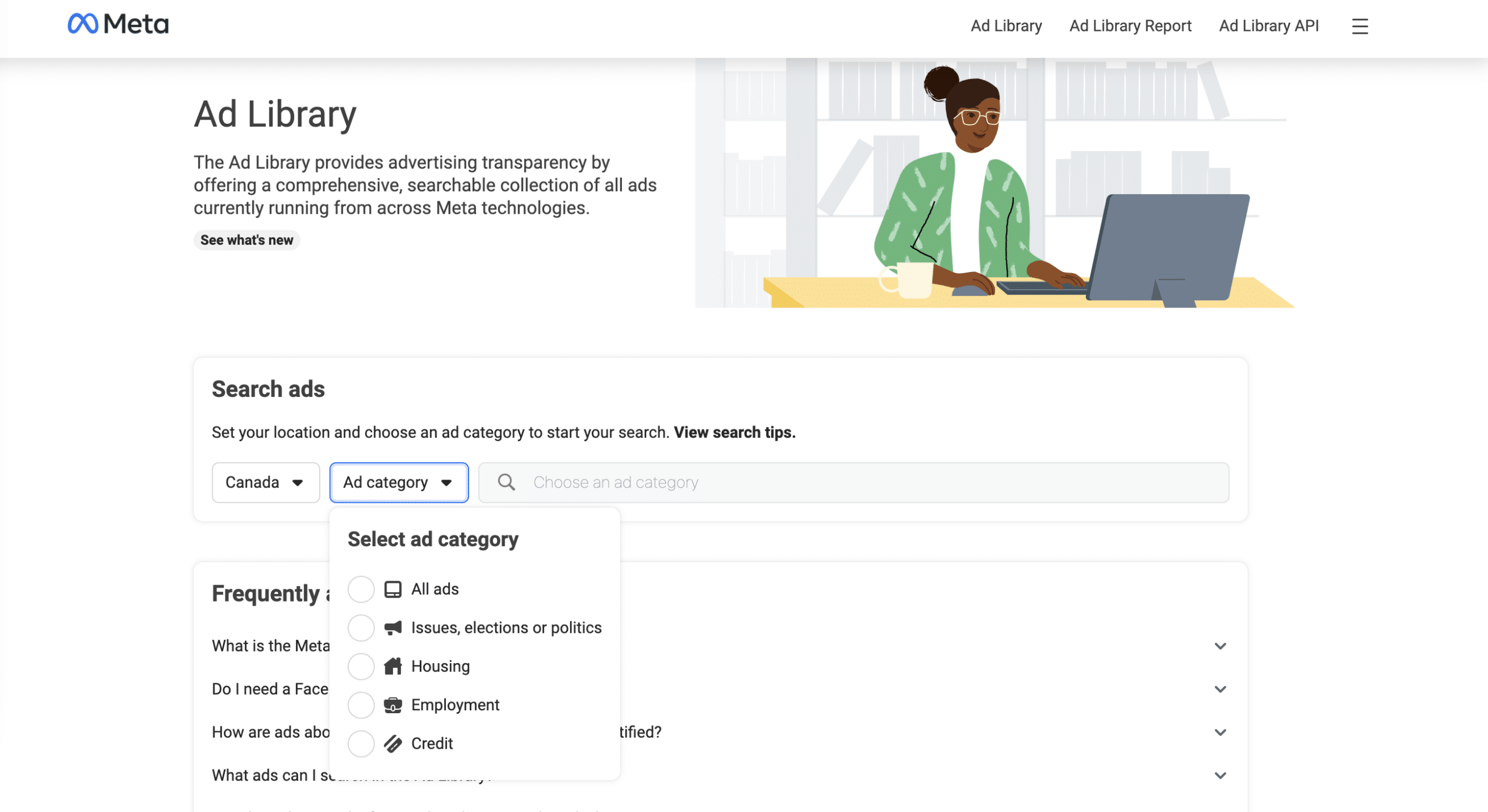
1. Giới thiệu về Facebook Ads Library
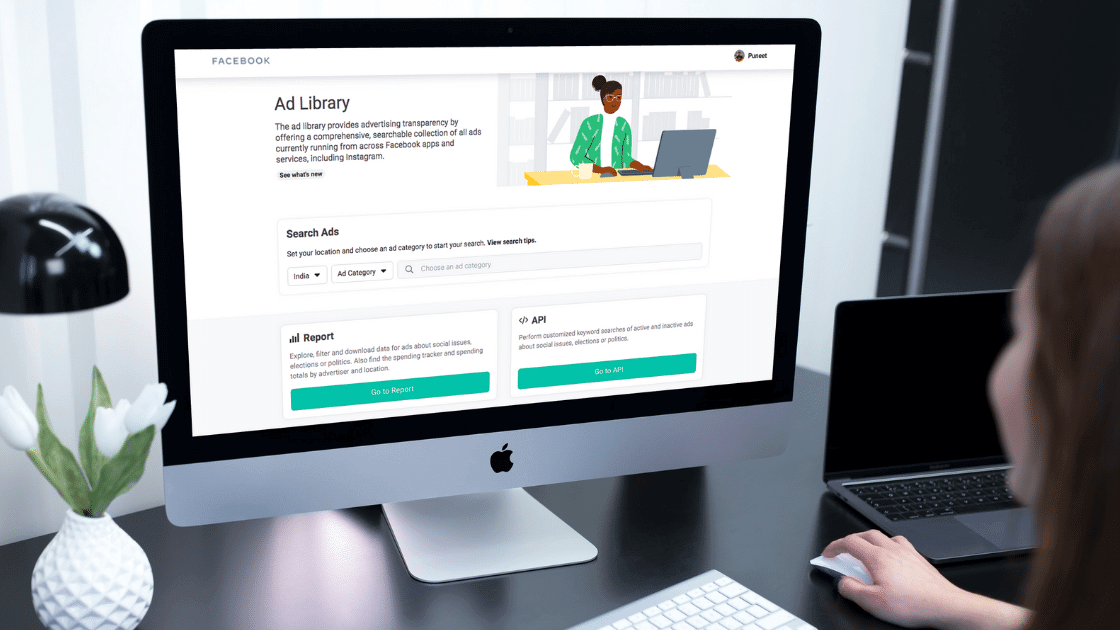
Facebook Ads Library là một công cụ miễn phí do Facebook cung cấp, cho phép người dùng truy cập và tìm kiếm các quảng cáo đang chạy trên các nền tảng của Facebook. Đây là một nguồn tài nguyên quý giá cho các nhà tiếp thị và doanh nghiệp nhằm phân tích và tối ưu hóa chiến dịch quảng cáo của họ.
Dưới đây là một số điểm nổi bật của Facebook Ads Library:
- Truy cập công khai: Bất kỳ ai cũng có thể truy cập và xem các quảng cáo đang chạy, bao gồm cả thông tin chi tiết về người đứng sau quảng cáo.
- Tính minh bạch: Facebook Ads Library cung cấp thông tin chi tiết về các quảng cáo chính trị và vấn đề xã hội, giúp tăng cường tính minh bạch trong quảng cáo.
- Phân loại quảng cáo: Quảng cáo được phân loại theo nhiều tiêu chí khác nhau, như ngành nghề, địa lý, và mục tiêu, giúp dễ dàng tìm kiếm và phân tích.
Một số lợi ích chính của việc sử dụng Facebook Ads Library:
- Phân tích đối thủ cạnh tranh: Bạn có thể xem các chiến dịch quảng cáo của đối thủ và học hỏi từ họ.
- Tối ưu hóa chiến dịch: Dựa trên dữ liệu thu thập, bạn có thể điều chỉnh và tối ưu hóa chiến dịch quảng cáo của mình để đạt hiệu quả cao hơn.
- Nghiên cứu thị trường: Thông tin từ Facebook Ads Library giúp bạn hiểu rõ hơn về xu hướng và nhu cầu của thị trường.
Ví dụ cụ thể về việc sử dụng Facebook Ads Library:
| Ứng dụng | Lợi ích |
| Nghiên cứu từ khóa | Xác định từ khóa hiệu quả dựa trên các quảng cáo hiện tại |
| Phân tích chiến dịch | So sánh và phân tích chiến dịch quảng cáo của bạn với đối thủ |
| Tạo quảng cáo mới | Lấy ý tưởng từ các quảng cáo thành công để tạo quảng cáo của riêng bạn |
Với những tính năng và lợi ích trên, Facebook Ads Library thực sự là một công cụ không thể thiếu cho bất kỳ ai muốn thành công trong lĩnh vực quảng cáo trực tuyến.
2. Tại sao nên scrape Facebook Ads Library
Scrape Facebook Ads Library là một phương pháp hữu ích để thu thập dữ liệu quảng cáo, giúp doanh nghiệp và nhà tiếp thị nắm bắt thông tin chi tiết và tối ưu hóa chiến dịch của họ. Dưới đây là những lý do tại sao bạn nên thực hiện việc này:
- Phân tích đối thủ cạnh tranh: Việc scrape dữ liệu từ Facebook Ads Library cho phép bạn theo dõi và phân tích các chiến dịch quảng cáo của đối thủ cạnh tranh, từ đó học hỏi và cải thiện chiến lược của mình.
- Tối ưu hóa chiến dịch: Dựa trên dữ liệu thu thập được, bạn có thể xác định những quảng cáo hiệu quả và điều chỉnh chiến dịch của mình để đạt kết quả tốt hơn.
- Nghiên cứu thị trường: Scrape dữ liệu giúp bạn nắm bắt xu hướng quảng cáo và thị hiếu của khách hàng, từ đó phát triển chiến lược tiếp cận phù hợp.
- Tiết kiệm thời gian: Việc tự động hóa quá trình thu thập dữ liệu giúp tiết kiệm thời gian so với việc tìm kiếm và phân tích thủ công.
Dưới đây là các bước chi tiết để scrape dữ liệu từ Facebook Ads Library:
- Cài đặt các công cụ cần thiết: Bạn cần cài đặt Python và các thư viện như BeautifulSoup và Selenium.
- Thiết lập môi trường làm việc: Thiết lập ChromeDriver để Selenium có thể tự động hóa trình duyệt web.
- Viết mã scrape dữ liệu: Sử dụng Python và các thư viện đã cài đặt để viết mã scrape dữ liệu từ Facebook Ads Library.
- Phân tích và lưu trữ dữ liệu: Sau khi thu thập dữ liệu, bạn có thể sử dụng Pandas để phân tích và lưu trữ dữ liệu vào các định dạng như CSV hoặc JSON.
Một số lợi ích cụ thể của việc scrape dữ liệu từ Facebook Ads Library:
| Lợi ích | Mô tả |
| Hiểu rõ đối thủ | Nắm bắt chiến lược quảng cáo của đối thủ và điều chỉnh kế hoạch của bạn |
| Tối ưu ngân sách | Xác định quảng cáo hiệu quả để tối ưu hóa chi phí quảng cáo |
| Nâng cao hiệu suất | Dựa trên dữ liệu thu thập để cải thiện hiệu suất chiến dịch |
Nhìn chung, việc scrape Facebook Ads Library mang lại nhiều lợi ích đáng kể, giúp bạn nắm bắt thông tin quan trọng và tối ưu hóa chiến lược quảng cáo một cách hiệu quả.

3. Các công cụ hỗ trợ scrape dữ liệu
Việc scrape dữ liệu từ Facebook Ads Library yêu cầu các công cụ và thư viện mạnh mẽ để truy xuất và xử lý thông tin một cách hiệu quả. Dưới đây là các công cụ và thư viện phổ biến thường được sử dụng:
-
3.1. Python
Python là một ngôn ngữ lập trình mạnh mẽ và linh hoạt, rất phổ biến trong việc phát triển các ứng dụng web scraping. Python có cú pháp đơn giản và thư viện phong phú hỗ trợ việc lấy và xử lý dữ liệu.
-
3.2. BeautifulSoup
BeautifulSoup là một thư viện Python dùng để phân tích cú pháp HTML và XML. Nó cho phép bạn trích xuất dữ liệu từ các trang web một cách dễ dàng và hiệu quả.
- Dễ dàng cài đặt và sử dụng
- Hỗ trợ nhiều phương pháp tìm kiếm và phân tích dữ liệu
-
3.3. Selenium
Selenium là một công cụ tự động hóa web, giúp bạn điều khiển trình duyệt để thực hiện các tác vụ như người dùng thật. Selenium thường được sử dụng để scrape các trang web có JavaScript động.
Ưu điểm Nhược điểm Có thể điều khiển các trình duyệt phổ biến như Chrome, Firefox Chạy chậm hơn so với các phương pháp khác Hỗ trợ các thao tác phức tạp như click, điền form Yêu cầu cấu hình và cài đặt nhiều hơn -
3.4. ChromeDriver
ChromeDriver là một công cụ điều khiển trình duyệt Chrome từ Selenium. Để sử dụng Selenium với Chrome, bạn cần cài đặt ChromeDriver.
- Download ChromeDriver từ trang chủ chính thức
- Giải nén và đặt đường dẫn tới ChromeDriver trong biến môi trường
- Sử dụng ChromeDriver trong mã nguồn Selenium để điều khiển trình duyệt Chrome

4. Hướng dẫn cài đặt và thiết lập công cụ
Để bắt đầu quá trình scrape dữ liệu từ Facebook Ads Library, bạn cần cài đặt và thiết lập các công cụ sau:
4.1. Cài đặt Python và thư viện BeautifulSoup
-
Cài đặt Python: Truy cập trang web chính thức của Python () và tải về phiên bản mới nhất phù hợp với hệ điều hành của bạn. Sau khi tải về, hãy thực hiện cài đặt theo hướng dẫn trên trang web.
-
Cài đặt BeautifulSoup: Sau khi đã cài đặt Python, mở terminal hoặc command prompt và nhập lệnh sau để cài đặt BeautifulSoup:
pip install beautifulsoup4
4.2. Cài đặt Selenium và ChromeDriver
-
Cài đặt Selenium: Tương tự như BeautifulSoup, bạn cần cài đặt Selenium bằng cách mở terminal hoặc command prompt và nhập lệnh sau:
pip install selenium -
Cài đặt ChromeDriver: Truy cập trang web chính thức của ChromeDriver () và tải về phiên bản phù hợp với phiên bản trình duyệt Chrome của bạn. Sau khi tải về, giải nén tệp và lưu lại đường dẫn đến tệp
chromedriver.exeđể sử dụng trong các bước tiếp theo.
4.3. Thiết lập môi trường làm việc
-
Tạo một thư mục mới cho dự án scrape dữ liệu của bạn. Mở terminal hoặc command prompt, điều hướng đến thư mục này và tạo một virtual environment bằng lệnh:
python -m venv myenv -
Kích hoạt virtual environment:
- Trên Windows:
myenv\Scripts\activate - Trên macOS/Linux:
source myenv/bin/activate
- Trên Windows:
-
Cài đặt các thư viện cần thiết (requests, tqdm) trong virtual environment:
pip install requests tqdm
Với các công cụ đã được cài đặt và thiết lập, bạn đã sẵn sàng để tiến hành các bước scrape dữ liệu từ Facebook Ads Library.

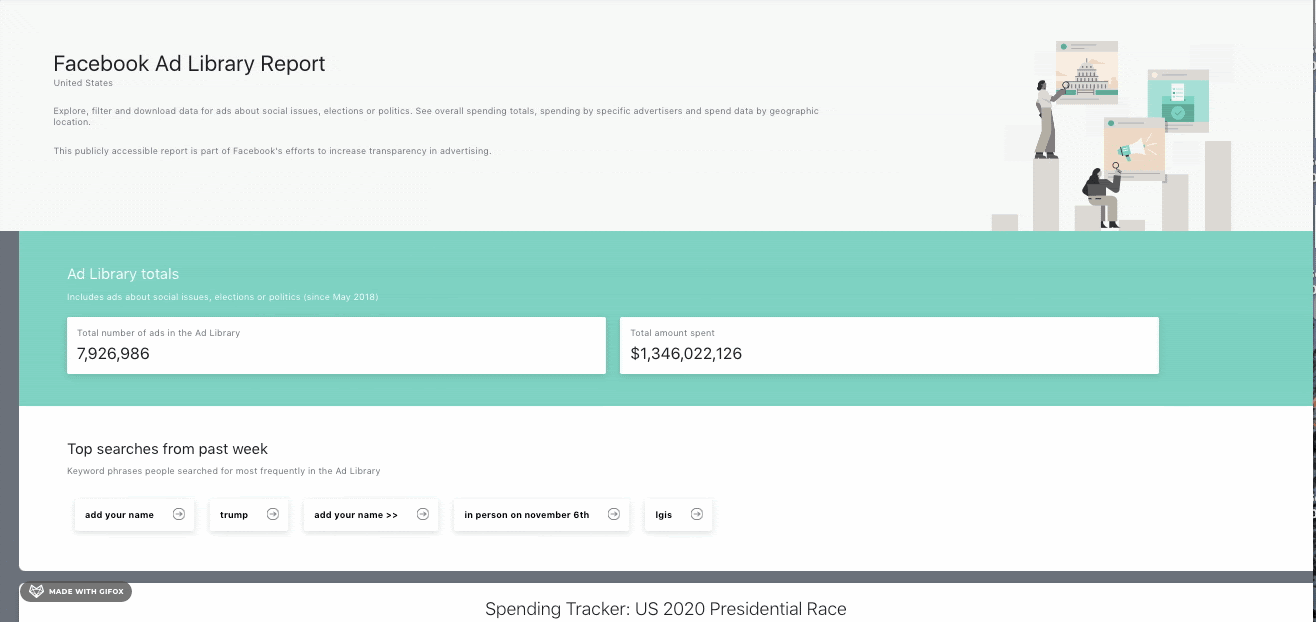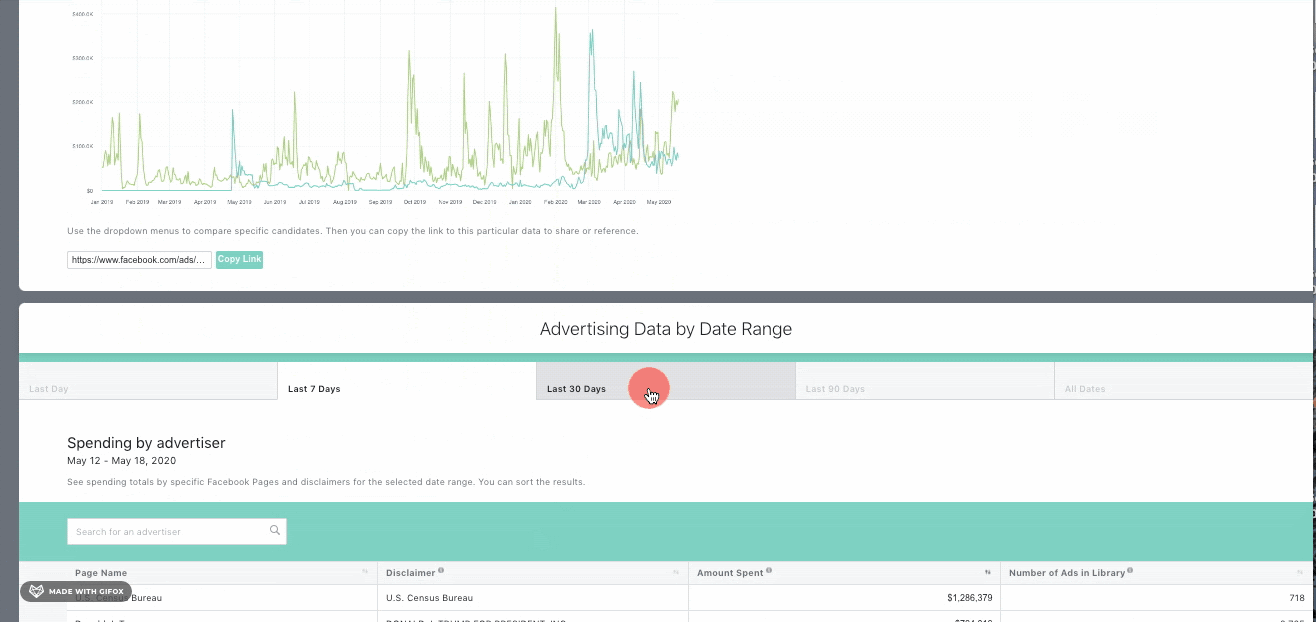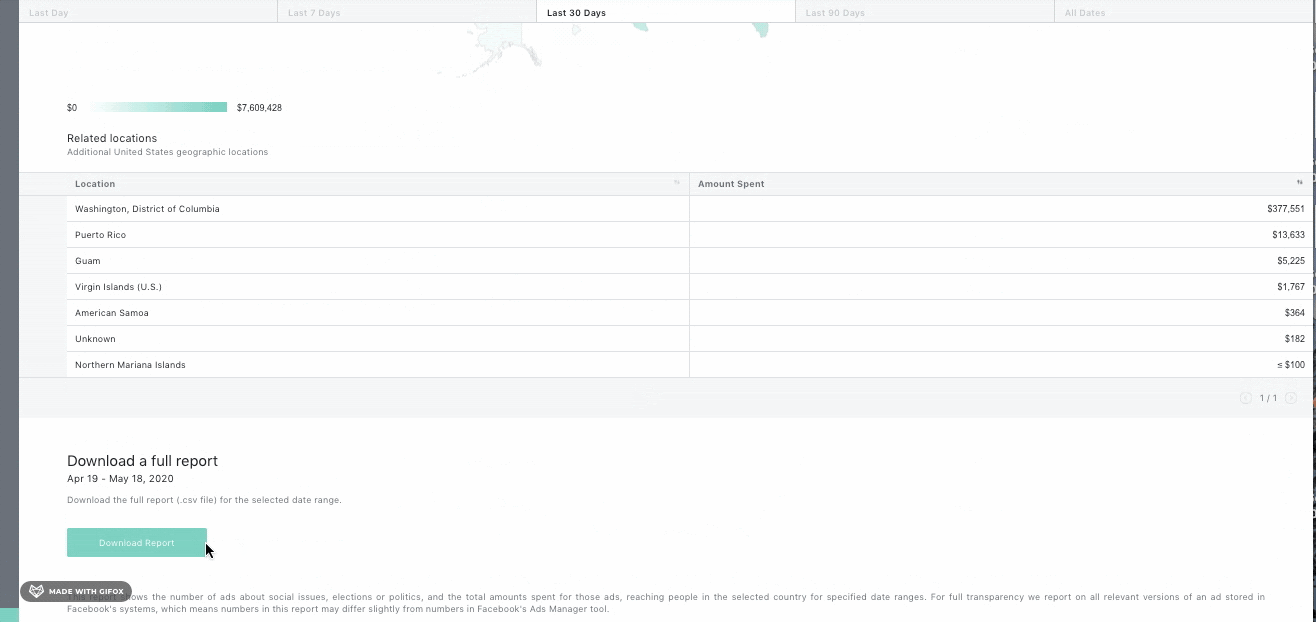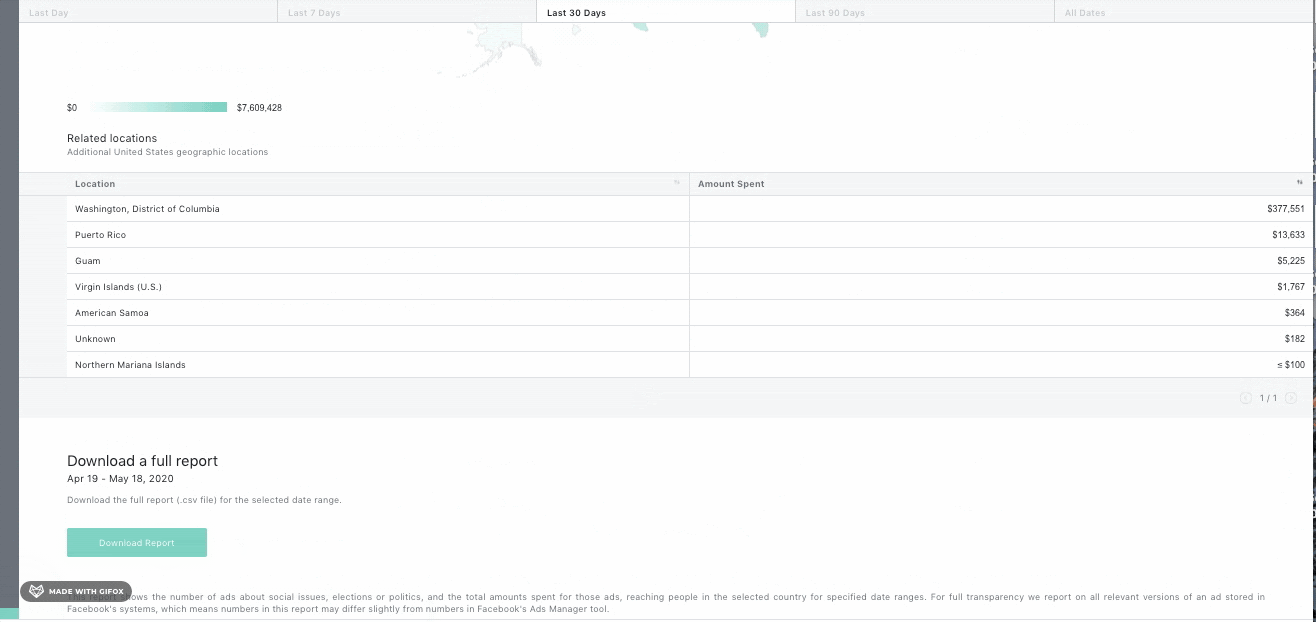
5. Các bước tiến hành scrape dữ liệu
Scraping dữ liệu từ Facebook Ads Library là quá trình thú vị và bổ ích. Dưới đây là các bước chi tiết để thực hiện việc này:
-
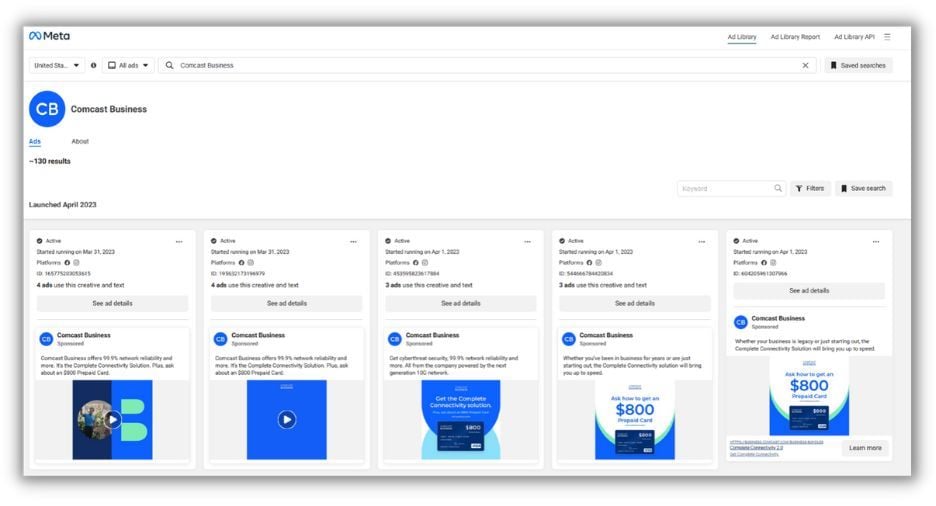
Truy cập Facebook Ads Library
Đầu tiên, bạn cần truy cập vào . Tại đây, bạn có thể tìm kiếm các quảng cáo bằng cách nhập tên trang hoặc từ khóa liên quan.
-
Lấy nội dung trang
Sau khi đã tìm được quảng cáo mong muốn, sao chép URL từ thanh địa chỉ của trình duyệt. URL này sẽ được sử dụng để lấy nội dung quảng cáo.
-
Phân tích và lấy dữ liệu quảng cáo
Sử dụng công cụ scrape, chẳng hạn như Apify hoặc BeautifulSoup trong Python, để trích xuất dữ liệu từ URL. Dưới đây là ví dụ về cách sử dụng BeautifulSoup:
from bs4 import BeautifulSoup import requests url = 'URL_CUA_QUANG_CAO' response = requests.get(url) soup = BeautifulSoup(response.content, 'html.parser') # Lấy thông tin quảng cáo ads_data = soup.find_all('div', class_='ads_data_class') # Thay thế 'ads_data_class' bằng class thực tế for ad in ads_data: print(ad.text)Sử dụng Apify, bạn có thể cấu hình và chạy scraper bằng cách:
- Chọn "Try for free" trên trang Apify
- Nhập URL kết quả tìm kiếm từ Facebook Ads Library
- Chọn "Scrape ad details" nếu cần thông tin chi tiết
- Chọn proxy và bắt đầu scraper
- Xuất dữ liệu sau khi hoàn thành
Ví dụ mã nguồn với Selenium
Dưới đây là một ví dụ sử dụng Selenium để tự động hóa quá trình trích xuất dữ liệu:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get('URL_CUA_QUANG_CAO')
ads = driver.find_elements(By.CLASS_NAME, 'ads_data_class') # Thay thế 'ads_data_class' bằng class thực tế
for ad in ads:
print(ad.text)
driver.quit()Phân tích dữ liệu thu thập
Sau khi đã thu thập dữ liệu, bạn có thể sử dụng các công cụ phân tích dữ liệu như Pandas để xử lý và lưu trữ dữ liệu:
import pandas as pd
data = {'ads_content': ads_content_list} # ads_content_list chứa dữ liệu quảng cáo thu thập được
df = pd.DataFrame(data)
df.to_csv('ads_data.csv', index=False)Với các bước trên, bạn sẽ có thể thu thập và phân tích dữ liệu quảng cáo từ Facebook Ads Library một cách hiệu quả. Hãy nhớ tuân thủ các điều khoản dịch vụ của Facebook và chỉ sử dụng dữ liệu vào mục đích hợp pháp và có trách nhiệm.
XEM THÊM:
6. Xử lý và lưu trữ dữ liệu
Trong phần này, chúng ta sẽ thảo luận về cách xử lý và lưu trữ dữ liệu đã scrape từ Facebook Ads Library. Chúng ta sẽ sử dụng Pandas để xử lý dữ liệu và lưu trữ dữ liệu vào các định dạng phổ biến như CSV và JSON.
6.1. Sử dụng Pandas để xử lý dữ liệu
Pandas là một thư viện mạnh mẽ trong Python để phân tích và xử lý dữ liệu. Dưới đây là các bước để xử lý dữ liệu bằng Pandas:
- Đầu tiên, import thư viện Pandas:
import pandas as pd - Đọc dữ liệu từ file JSON đã scrape:
data = pd.read_json('path_to_your_scraped_data.json') - Xem qua dữ liệu:
print(data.head()) - Xử lý và làm sạch dữ liệu nếu cần thiết, ví dụ như loại bỏ các cột không cần thiết:
data_cleaned = data.drop(columns=['unnecessary_column'])
6.2. Lưu trữ dữ liệu vào định dạng CSV
Sau khi xử lý dữ liệu, bạn có thể lưu trữ dữ liệu vào định dạng CSV để dễ dàng chia sẻ và phân tích. Các bước thực hiện như sau:
- Lưu dữ liệu vào file CSV:
data_cleaned.to_csv('path_to_save_your_data.csv', index=False)
6.3. Lưu trữ dữ liệu vào định dạng JSON
Định dạng JSON rất hữu ích để lưu trữ và truyền tải dữ liệu. Bạn có thể lưu dữ liệu vào file JSON như sau:
- Lưu dữ liệu vào file JSON:
data_cleaned.to_json('path_to_save_your_data.json', orient='records', lines=True)
Việc sử dụng Pandas giúp cho quá trình xử lý và lưu trữ dữ liệu trở nên đơn giản và hiệu quả. Bạn có thể dễ dàng phân tích và chia sẻ dữ liệu đã scrape từ Facebook Ads Library để thu được những thông tin quý giá cho chiến lược quảng cáo của mình.

7. Các lưu ý quan trọng khi scrape dữ liệu
Khi tiến hành scrape dữ liệu từ Facebook Ads Library, có một số lưu ý quan trọng mà bạn cần phải xem xét để đảm bảo quá trình diễn ra suôn sẻ và tuân thủ đúng quy định. Dưới đây là các lưu ý quan trọng cần ghi nhớ:
7.1. Tuân thủ điều khoản dịch vụ của Facebook
Điều đầu tiên và quan trọng nhất là phải tuân thủ các điều khoản dịch vụ của Facebook. Scrape dữ liệu mà không có sự cho phép có thể vi phạm chính sách của Facebook và dẫn đến việc tài khoản của bạn bị khóa hoặc bị cấm. Luôn kiểm tra và đảm bảo rằng bạn không vi phạm bất kỳ quy định nào của nền tảng.
7.2. Giới hạn số lượng yêu cầu
Để tránh bị phát hiện và chặn bởi Facebook, bạn nên giới hạn số lượng yêu cầu gửi đi trong một khoảng thời gian nhất định. Ví dụ:
- Chỉ gửi tối đa 100 yêu cầu mỗi giờ.
- Đặt khoảng thời gian nghỉ giữa các yêu cầu để không tạo ra quá nhiều lưu lượng truy cập đồng thời.
7.3. Phương pháp scrape dữ liệu có trách nhiệm
Scrape dữ liệu có trách nhiệm không chỉ giúp bạn tránh bị chặn mà còn giúp bảo vệ tài nguyên của Facebook. Một số phương pháp scrape có trách nhiệm bao gồm:
- Sử dụng IP xoay vòng để tránh bị phát hiện.
- Không tải về toàn bộ trang web mà chỉ lấy những phần cần thiết.
- Kiểm tra và đảm bảo dữ liệu scrape không vi phạm quyền riêng tư của người dùng.
7.4. Sử dụng các công cụ và kỹ thuật tiên tiến
Sử dụng các công cụ và kỹ thuật scrape tiên tiến như BeautifulSoup, Selenium, hoặc Scrapy có thể giúp bạn scrape dữ liệu hiệu quả hơn. Dưới đây là một bảng so sánh các công cụ này:
| Công cụ | Ưu điểm | Nhược điểm |
|---|---|---|
| BeautifulSoup | Dễ sử dụng, phù hợp với các dự án nhỏ | Không phù hợp với các trang web động |
| Selenium | Có thể tương tác với các trang web động | Chạy chậm hơn so với các công cụ khác |
| Scrapy | Hiệu quả cao, hỗ trợ tốt cho các dự án lớn | Đòi hỏi kiến thức lập trình sâu |
7.5. Bảo mật dữ liệu
Cuối cùng, hãy luôn bảo mật dữ liệu mà bạn đã scrape được. Lưu trữ dữ liệu một cách an toàn và sử dụng các phương pháp mã hóa để bảo vệ thông tin khỏi việc truy cập trái phép.
Bằng cách tuân thủ các lưu ý trên, bạn có thể scrape dữ liệu từ Facebook Ads Library một cách hiệu quả và an toàn.
8. Các ví dụ cụ thể về mã nguồn scrape dữ liệu
Dưới đây là các ví dụ cụ thể về mã nguồn sử dụng để scrape dữ liệu từ Facebook Ads Library, bao gồm mã nguồn Python cơ bản, mã nguồn với Selenium, và mã nguồn kết hợp BeautifulSoup.
8.1. Mã nguồn Python cơ bản
Đoạn mã Python cơ bản dưới đây sử dụng thư viện requests để gửi yêu cầu HTTP và lấy nội dung trang web.
import requests
url = "https://www.facebook.com/ads/library"
response = requests.get(url)
if response.status_code == 200:
print(response.text)
else:
print("Failed to retrieve the webpage")8.2. Mã nguồn với Selenium
Selenium là một công cụ mạnh mẽ để tự động hóa các tương tác với trình duyệt web. Đoạn mã dưới đây cho thấy cách sử dụng Selenium để truy cập Facebook Ads Library và lấy nội dung của trang.
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get("https://www.facebook.com/ads/library")
# Tìm kiếm và lấy dữ liệu từ phần tử cần thiết
ads = driver.find_elements(By.CLASS_NAME, "ad_container")
for ad in ads:
print(ad.text)
driver.quit()8.3. Mã nguồn kết hợp BeautifulSoup
BeautifulSoup giúp phân tích cú pháp HTML và trích xuất dữ liệu từ trang web một cách dễ dàng. Dưới đây là đoạn mã sử dụng BeautifulSoup để trích xuất dữ liệu quảng cáo từ nội dung HTML.
from bs4 import BeautifulSoup
import requests
url = "https://www.facebook.com/ads/library"
response = requests.get(url)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'html.parser')
ads = soup.find_all("div", class_="ad_container")
for ad in ads:
print(ad.text)
else:
print("Failed to retrieve the webpage")8.4. Mã nguồn sử dụng Scrapy
Scrapy là một framework mạnh mẽ cho web scraping. Dưới đây là ví dụ về cách sử dụng Scrapy để thu thập dữ liệu quảng cáo từ Facebook Ads Library.
import scrapy
class FacebookAdsSpider(scrapy.Spider):
name = "fb_ad_scraper"
start_urls = ["https://www.facebook.com/ads/library"]
def parse(self, response):
ads = response.css("div.ad_container")
for ad in ads:
yield {
"text": ad.css("div.text::text").get(),
"reactions": ad.css("span.reactions::text").get(),
"comments": ad.css("span.comments::text").get(),
}
# Chạy spider và lưu kết quả vào file JSON
# scrapy crawl fb_ad_scraper -o results.json8.5. Mã nguồn lưu trữ dữ liệu vào MongoDB
Đoạn mã dưới đây cho thấy cách lưu trữ dữ liệu quảng cáo vào MongoDB sau khi đã scrape.
import pymongo
class MongoDBPipeline(object):
def __init__(self):
client = pymongo.MongoClient('mongodb://localhost:27017')
self.mongo_db = client["fb_ads"]
def process_item(self, item, spider):
self.mongo_db["ad_data"].insert_one(dict(item))
return item8.6. Mã nguồn lập lịch với Airflow
Cuối cùng, bạn có thể lập lịch cho công việc scrape dữ liệu bằng Airflow để đảm bảo dữ liệu luôn được cập nhật.
from airflow import DAG
from airflow.operators.python_operator import PythonOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'Facebook Ads',
'depends_on_past': False,
'start_date': datetime(2024, 1, 1),
'retries': 1,
'retry_delay': timedelta(minutes=5)
}
dag = DAG(
'facebook_ads',
default_args=default_args,
schedule_interval='0 0 * * *', # Chạy hàng ngày
)
def run_facebook_scraper():
# Đoạn mã scrape dữ liệu
pass
run_scraper = PythonOperator(
task_id='run_fb_scraper',
python_callable=run_facebook_scraper,
dag=dag
)9. Tổng kết và khuyến nghị
Việc scrape dữ liệu từ Facebook Ads Library mang lại nhiều lợi ích cho các nhà quảng cáo và nhà nghiên cứu, giúp họ nắm bắt được các chiến lược quảng cáo của đối thủ và tối ưu hóa chiến dịch của mình. Dưới đây là một số khuyến nghị quan trọng khi thực hiện quá trình này:
- Tuân thủ điều khoản dịch vụ: Hãy đảm bảo bạn luôn tuân thủ điều khoản dịch vụ của Facebook khi thực hiện việc scrape dữ liệu để tránh vi phạm và bị khóa tài khoản.
- Sử dụng công cụ phù hợp: Chọn các công cụ như Python, BeautifulSoup, và Selenium để tự động hóa và hiệu quả hóa quá trình scrape dữ liệu.
- Phân tích dữ liệu có trách nhiệm: Sau khi thu thập dữ liệu, hãy phân tích một cách có trách nhiệm và sử dụng dữ liệu này để cải thiện chiến lược quảng cáo của bạn mà không vi phạm quyền riêng tư của người dùng.
Quá trình scrape dữ liệu từ Facebook Ads Library có thể chia thành các bước sau:
- Truy cập Facebook Ads Library: Bắt đầu bằng việc truy cập trang Facebook Ads Library và tìm kiếm các quảng cáo của đối thủ.
- Lấy nội dung trang: Sử dụng các công cụ để thu thập nội dung trang quảng cáo, bao gồm các thông tin về nội dung, hình ảnh, và các tham số mục tiêu.
- Xử lý và lưu trữ dữ liệu: Sử dụng Pandas để xử lý dữ liệu và lưu trữ vào các định dạng như CSV hoặc JSON để dễ dàng quản lý và phân tích.
Các ví dụ cụ thể về mã nguồn scrape dữ liệu đã được trình bày trong các phần trước, bao gồm các ví dụ về mã nguồn Python cơ bản, mã nguồn với Selenium, và mã nguồn kết hợp BeautifulSoup. Những ví dụ này cung cấp nền tảng vững chắc để bạn bắt đầu và phát triển các công cụ của riêng mình.
Tổng kết lại, việc scrape dữ liệu từ Facebook Ads Library là một phương pháp mạnh mẽ để nắm bắt và tối ưu hóa chiến lược quảng cáo. Bằng cách sử dụng các công cụ phù hợp và tuân thủ các nguyên tắc quan trọng, bạn có thể tận dụng tối đa những thông tin quý giá này để phát triển kinh doanh của mình một cách hiệu quả và bền vững.
Chúc các bạn thành công!

Cách scrape dữ liệu từ thư viện quảng cáo Facebook bằng Node.js
FB Ads Library Scraper | Script Python (Hoạt động 100%)
.webp)

.jpg)








 Blender Room - Cách Tạo Không Gian 3D Tuyệt Đẹp Bằng Blender
Blender Room - Cách Tạo Không Gian 3D Tuyệt Đẹp Bằng Blender Setting V-Ray 5 Cho 3ds Max: Hướng Dẫn Tối Ưu Hiệu Quả Render
Setting V-Ray 5 Cho 3ds Max: Hướng Dẫn Tối Ưu Hiệu Quả Render D5 Converter 3ds Max: Hướng Dẫn Chi Tiết Và Các Tính Năng Nổi Bật
D5 Converter 3ds Max: Hướng Dẫn Chi Tiết Và Các Tính Năng Nổi Bật Xóa Lịch Sử Chrome Trên Máy Tính: Hướng Dẫn Chi Tiết Và Hiệu Quả
Xóa Lịch Sử Chrome Trên Máy Tính: Hướng Dẫn Chi Tiết Và Hiệu Quả VLC Media Player Android: Hướng Dẫn Chi Tiết và Tính Năng Nổi Bật
VLC Media Player Android: Hướng Dẫn Chi Tiết và Tính Năng Nổi Bật Chuyển File Canva Sang AI: Hướng Dẫn Nhanh Chóng và Đơn Giản Cho Người Mới Bắt Đầu
Chuyển File Canva Sang AI: Hướng Dẫn Nhanh Chóng và Đơn Giản Cho Người Mới Bắt Đầu Chuyển từ Canva sang PowerPoint - Hướng dẫn chi tiết và hiệu quả
Chuyển từ Canva sang PowerPoint - Hướng dẫn chi tiết và hiệu quả Ghi Âm Zoom Trên Máy Tính: Hướng Dẫn Chi Tiết và Mẹo Hữu Ích
Ghi Âm Zoom Trên Máy Tính: Hướng Dẫn Chi Tiết và Mẹo Hữu Ích "Notion có tiếng Việt không?" - Hướng dẫn thiết lập và lợi ích khi sử dụng
"Notion có tiếng Việt không?" - Hướng dẫn thiết lập và lợi ích khi sử dụng Facebook No Ads XDA - Trải Nghiệm Không Quảng Cáo Đáng Thử
Facebook No Ads XDA - Trải Nghiệm Không Quảng Cáo Đáng Thử Autocad Alert: Giải Pháp Toàn Diện cho Mọi Thông Báo và Lỗi Thường Gặp
Autocad Alert: Giải Pháp Toàn Diện cho Mọi Thông Báo và Lỗi Thường Gặp Ký Hiệu Trên Bản Vẽ AutoCAD: Hướng Dẫn Toàn Diện và Thực Hành
Ký Hiệu Trên Bản Vẽ AutoCAD: Hướng Dẫn Toàn Diện và Thực Hành Tổng hợp lisp phục vụ bóc tách khối lượng xây dựng
Tổng hợp lisp phục vụ bóc tách khối lượng xây dựng Chỉnh kích thước số dim trong cad – cách đơn giản nhất 2024
Chỉnh kích thước số dim trong cad – cách đơn giản nhất 2024