Chủ đề nearest neighbor qgis: Nearest Neighbor trong QGIS là một công cụ mạnh mẽ hỗ trợ phân tích dữ liệu không gian. Bài viết này cung cấp hướng dẫn chi tiết về cách áp dụng phương pháp này, từ khái niệm cơ bản đến các ứng dụng thực tế trong quản lý tài nguyên và đô thị. Cùng tìm hiểu cách Nearest Neighbor cải thiện độ chính xác và hiệu quả của các dự án GIS.
Mục lục
Mục Lục
.png)
Khai niệm Nearest Neighbor
Nearest Neighbor, hay còn gọi là phân tích láng giềng gần nhất, là một phương pháp trong địa lý học và phân tích không gian nhằm tính toán khoảng cách từ một điểm đến điểm gần nhất trong một tập dữ liệu. Phương pháp này thường được sử dụng để đánh giá mức độ phân bố của các điểm trong không gian, từ đó giúp phân tích các yếu tố như mật độ dân cư, phân bố tài nguyên, hoặc tương tác giữa các yếu tố địa lý.
Trong QGIS, Nearest Neighbor được thực hiện qua công cụ Nearest Neighbour Analysis trong hộp công cụ xử lý. Các bước thực hiện như sau:
- Chọn lớp điểm đầu vào cần phân tích (ví dụ, một lớp điểm đại diện cho các vị trí tự nhiên).
- Cấu hình các thông số như lớp điểm đầu vào và đường dẫn file HTML kết quả đầu ra.
- Sau khi tính toán, kết quả sẽ trả về một file HTML chứa các thông số như:
- Khoảng cách trung bình quan sát (\(Observed\ mean\ distance\)).
- Khoảng cách trung bình kỳ vọng (\(Expected\ mean\ distance\)).
- Chỉ số láng giềng gần nhất (\(Nearest\ neighbor\ index\)).
- Số lượng điểm (\(Number\ of\ points\)).
- Z-Score (\(Z-Score\)).
Các thông số này sẽ giúp người dùng hiểu rõ hơn về sự phân bố không gian của các điểm, ví dụ, liệu các điểm có phân bố ngẫu nhiên, phân tán hay tập trung.
Công cụ này là một phần quan trọng trong phân tích địa lý không gian và thường được sử dụng trong nhiều lĩnh vực như quy hoạch đô thị, bảo tồn môi trường, và phân tích kinh tế xã hội.
Ứng dụng trong phân tích dữ liệu địa lý
Thuật toán K-Nearest Neighbor (KNN) là một công cụ mạnh mẽ trong việc phân tích dữ liệu địa lý khi sử dụng các phần mềm GIS, như QGIS. Nhờ vào khả năng phân loại và dự đoán dựa trên khoảng cách giữa các điểm dữ liệu, KNN giúp giải quyết nhiều bài toán liên quan đến không gian địa lý một cách chính xác và hiệu quả.
- Xác định điểm lân cận: KNN thường được sử dụng để tìm kiếm các điểm lân cận gần nhất với một điểm cụ thể. Ví dụ, trong QGIS, bạn có thể xác định vị trí các khu vực lân cận dựa trên tọa độ địa lý của các đối tượng dữ liệu, giúp phân tích kết nối giữa các vùng hoặc các địa điểm quan trọng.
- Phân loại dữ liệu địa lý: Trong một tập dữ liệu địa lý lớn, KNN hỗ trợ phân loại các vùng hoặc khu vực dựa trên các yếu tố như khoảng cách không gian và các đặc trưng khác nhau. Điều này đặc biệt hữu ích trong các nghiên cứu về môi trường, nơi mà việc xác định loại đất hoặc địa hình dựa trên dữ liệu không gian là rất quan trọng.
- Dự đoán các vùng chưa được khảo sát: KNN có thể giúp dự đoán đặc điểm của các vùng chưa được khảo sát dựa trên đặc điểm của các vùng lân cận đã được biết. Điều này có thể ứng dụng trong việc dự đoán sự phân bố của thực vật, động vật hoặc các yếu tố khác trong hệ sinh thái.
Quy trình ứng dụng KNN trong QGIS
- Chuẩn bị dữ liệu: Bước đầu tiên là thu thập và chuẩn bị dữ liệu không gian (các lớp vector hoặc raster). Sau đó, bạn cần xác định các điểm dữ liệu đầu vào cần phân tích.
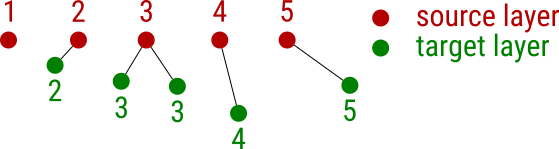
- Sử dụng công cụ KNN: Trong QGIS, có thể cài đặt các plugin như NNJoin để sử dụng thuật toán KNN. Công cụ này cho phép xác định khoảng cách giữa các điểm dữ liệu dựa trên tọa độ không gian và phân loại hoặc dự đoán dựa trên các điểm lân cận.
- Phân tích kết quả: Sau khi thực hiện tính toán KNN, kết quả phân tích sẽ hiển thị các điểm lân cận, các vùng hoặc các đặc điểm không gian được dự đoán. Bạn có thể sử dụng các công cụ hiển thị của QGIS để trực quan hóa các kết quả này trên bản đồ.
Nhờ vào sự kết hợp giữa KNN và QGIS, người dùng có thể phân tích dữ liệu địa lý một cách chi tiết, hỗ trợ các nghiên cứu và quyết định liên quan đến không gian.

Quy trình áp dụng Nearest Neighbor trong QGIS
Phương pháp Nearest Neighbor là một trong những kỹ thuật phổ biến trong phân tích không gian địa lý, đặc biệt khi sử dụng phần mềm QGIS. Dưới đây là quy trình chi tiết từng bước để áp dụng thuật toán này trong QGIS:
- Chuẩn bị dữ liệu: Bước đầu tiên, người dùng cần thu thập và chuẩn bị các tập dữ liệu không gian như shapefile hoặc GeoJSON. Đây là các tập dữ liệu chứa thông tin tọa độ và thuộc tính của các đối tượng địa lý cần phân tích.
- Cài đặt plugin Nearest Neighbor: Trong QGIS, bạn cần cài đặt plugin NNJoin, một công cụ hỗ trợ việc tìm các điểm gần nhất giữa hai lớp dữ liệu không gian. Để cài đặt, vào Plugins > Manage and Install Plugins và tìm kiếm NNJoin.
- Chạy công cụ NNJoin: Sau khi cài đặt plugin, mở công cụ này từ menu Processing > Toolbox > NNJoin. Chọn lớp dữ liệu nguồn và lớp dữ liệu đích mà bạn muốn tính toán khoảng cách lân cận.
- Cấu hình thông số: Nhập các thông số cần thiết, chẳng hạn như số lượng điểm lân cận cần tìm, đơn vị đo khoảng cách, và các thuộc tính cần xuất ra trong kết quả.
- Thực hiện phân tích: Sau khi hoàn tất việc nhập thông số, nhấn Run để thực hiện phân tích. QGIS sẽ tính toán và xuất ra một lớp dữ liệu mới với các thuộc tính và thông tin về khoảng cách lân cận.
- Kiểm tra kết quả: Sau khi hoàn thành, lớp dữ liệu mới sẽ hiển thị trên bản đồ với các điểm lân cận được kết nối và các thuộc tính khoảng cách được lưu trữ trong bảng thuộc tính.
Quy trình trên giúp người dùng dễ dàng áp dụng phương pháp Nearest Neighbor để phân tích dữ liệu không gian một cách nhanh chóng và chính xác trong QGIS.

Phân tích kết quả Nearest Neighbor
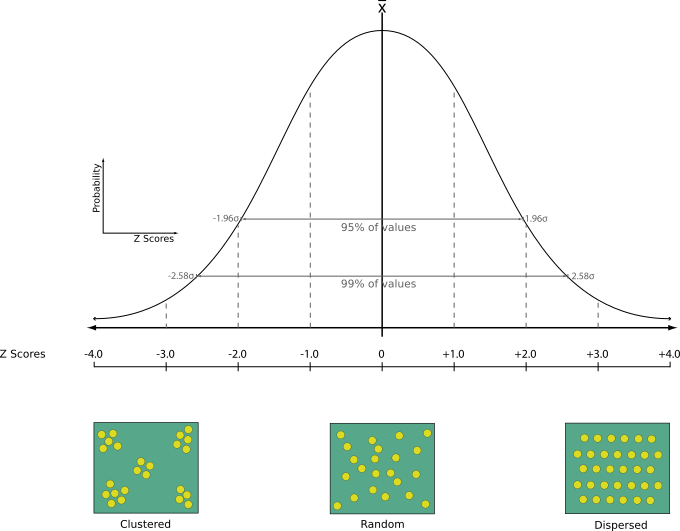
Trong phân tích không gian địa lý, thuật toán Nearest Neighbor (láng giềng gần nhất) là một công cụ hữu ích trong QGIS để đo lường sự phân bố của các điểm trong một không gian. Sau khi tính toán, bạn sẽ nhận được giá trị Nearest Neighbor Index (NNI), giúp xác định mức độ phân bố của các điểm theo ba xu hướng chính: cụm, ngẫu nhiên, hoặc phân tán.
- Nếu NNI < 1: Các điểm có xu hướng tạo thành cụm.
- Nếu NNI = 1: Các điểm phân bố ngẫu nhiên.
- Nếu NNI > 1: Các điểm có xu hướng phân tán đồng đều.
Kết quả của phân tích này cung cấp một cách tiếp cận định lượng để đánh giá sự tương tác giữa các yếu tố địa lý. Ví dụ, trong phân tích địa lý của các tòa nhà hoặc cây cối, việc tính toán NNI giúp hiểu rõ hơn sự phân bố của chúng, từ đó có thể đưa ra các quyết định quản lý phù hợp.
Việc giải thích kết quả Nearest Neighbor cần xem xét đến ngữ cảnh của dữ liệu, chẳng hạn như loại hình dữ liệu (điểm, đường, hay vùng) và mục đích phân tích. Đôi khi, kết quả cụm hay phân tán có thể gợi ý về những tác động môi trường hoặc xã hội nhất định.
- Bước 1: Thu thập và nhập dữ liệu điểm vào QGIS.
- Bước 2: Sử dụng công cụ Nearest Neighbor Analysis có sẵn trong QGIS.
- Bước 3: Phân tích kết quả và so sánh với các mẫu phân bố lý thuyết.
Kết quả phân tích không chỉ giúp bạn hiểu rõ hơn về cấu trúc không gian mà còn có thể hỗ trợ trong việc ra quyết định về quản lý tài nguyên hoặc quy hoạch đô thị một cách hiệu quả.

Thuật toán K-Nearest Neighbor (KNN)
Thuật toán K-Nearest Neighbor (KNN) là một trong những phương pháp học máy dựa trên sự gần gũi về mặt không gian giữa các điểm dữ liệu. Nguyên lý cơ bản của KNN là sử dụng thông tin từ các điểm dữ liệu lân cận để dự đoán hoặc phân loại dữ liệu mới.
Nguyên lý hoạt động của KNN
Nguyên lý hoạt động của KNN rất đơn giản nhưng hiệu quả. Khi có một điểm dữ liệu mới cần phân loại, KNN sẽ tìm kiếm k điểm gần nhất trong không gian tính năng và sử dụng nhãn của các điểm này để đưa ra dự đoán. Cụ thể, với mỗi điểm dữ liệu mới \(X\), thuật toán sẽ tính toán khoảng cách giữa \(X\) và từng điểm dữ liệu trong tập huấn luyện, sau đó chọn ra \(k\) điểm có khoảng cách ngắn nhất.
- Kết quả phân loại: Điểm dữ liệu mới được gán nhãn theo đa số các điểm lân cận.
- Khoảng cách: KNN thường sử dụng khoảng cách Euclid \[ d(x, y) = \sqrt{\sum_{i=1}^{n} (x_i - y_i)^2} \] để đo khoảng cách giữa các điểm dữ liệu.
Áp dụng KNN trong các mô hình GIS
Trong các mô hình GIS, KNN được sử dụng để phân loại không gian và phân tích các thuộc tính địa lý dựa trên sự tương đồng về mặt không gian. Một số ứng dụng phổ biến của KNN trong GIS bao gồm:
- Phân loại sử dụng đất: Dựa trên thuộc tính và khoảng cách không gian của các khu vực khác nhau, KNN có thể dự đoán loại hình sử dụng đất cho các vùng chưa được phân loại.
- Phân tích biến đổi địa lý: Sử dụng KNN để phát hiện các thay đổi trong phân bố dân cư hoặc sự thay đổi của các vùng đất dựa trên dữ liệu lân cận.
- Đánh giá rủi ro: KNN giúp phân tích các yếu tố rủi ro (như lũ lụt, động đất) dựa trên dữ liệu lân cận về môi trường và hạ tầng.
Ưu điểm và hạn chế của KNN
KNN có nhiều ưu điểm, nhưng cũng đi kèm với một số hạn chế.
- Ưu điểm:
- Dễ hiểu và dễ triển khai.
- Không yêu cầu giả định về phân phối dữ liệu.
- Thích hợp cho các bài toán có không gian dữ liệu phức tạp.
- Hạn chế:
- Độ phức tạp cao khi số lượng dữ liệu lớn do phải tính khoảng cách giữa các điểm.
- Kết quả phụ thuộc vào giá trị của k, cần phải lựa chọn một giá trị phù hợp.
Lựa chọn giá trị k
Việc chọn giá trị k là một yếu tố quan trọng trong thuật toán KNN. Một giá trị \(k\) nhỏ có thể làm tăng khả năng mô hình bị ảnh hưởng bởi nhiễu, trong khi một giá trị \(k\) lớn hơn có thể làm cho biên giới giữa các lớp không rõ ràng. Thông thường, giá trị \(k\) được chọn thông qua quá trình thử nghiệm với các tập dữ liệu khác nhau.
XEM THÊM:
Tài nguyên và Plugin hỗ trợ
QGIS là một công cụ mạnh mẽ trong phân tích không gian và có sẵn nhiều tài nguyên cùng plugin hỗ trợ việc phân tích hàng xóm gần nhất (nearest neighbor analysis). Những plugin và tài nguyên này giúp người dùng khai thác đầy đủ khả năng của phần mềm để xử lý các tác vụ phức tạp liên quan đến mối quan hệ không gian giữa các đối tượng.
- Distance Matrix: Công cụ "Distance Matrix" có sẵn trong QGIS là một trong những phương pháp phổ biến để phân tích hàng xóm gần nhất. Bạn có thể tìm thấy nó tại Vector > Analysis Tools > Distance Matrix. Công cụ này tạo ra một ma trận khoảng cách giữa các điểm trong lớp dữ liệu và cho phép bạn chọn số lượng điểm gần nhất (ví dụ: chỉ lấy 1 điểm gần nhất).
- Plugin NNJoin: Đây là một plugin phổ biến hỗ trợ việc tính toán hàng xóm gần nhất. Plugin này cho phép kết hợp các thuộc tính của điểm gần nhất từ một lớp vào một lớp khác, điều này rất hữu ích khi bạn cần bổ sung dữ liệu dựa trên khoảng cách giữa các đối tượng.
- Plugin Distance to Nearest Hub: Plugin này cung cấp chức năng tính toán khoảng cách từ các điểm trong một lớp đến đối tượng gần nhất trong một lớp khác. Đây là một công cụ hữu ích khi làm việc với dữ liệu không gian về giao thông, vị trí dịch vụ, hoặc các trung tâm quan trọng.
- Plugin NNJoin và CSV: Ngoài việc sử dụng plugin, một cách tiếp cận khác là xuất dữ liệu khoảng cách sang file CSV và kết hợp thông tin này lại trong bảng thuộc tính thông qua công cụ Delimited Text Layer của QGIS. Việc này giúp tạo ra các lớp dữ liệu kết hợp với các thông tin về hàng xóm gần nhất.
Với những công cụ và plugin hỗ trợ trên, QGIS trở thành một nền tảng linh hoạt cho việc phân tích và xử lý dữ liệu không gian. Việc sử dụng các công cụ như ma trận khoảng cách và các plugin sẽ giúp cải thiện đáng kể hiệu suất và độ chính xác trong các bài toán liên quan đến hàng xóm gần nhất.










 Blender Room - Cách Tạo Không Gian 3D Tuyệt Đẹp Bằng Blender
Blender Room - Cách Tạo Không Gian 3D Tuyệt Đẹp Bằng Blender Setting V-Ray 5 Cho 3ds Max: Hướng Dẫn Tối Ưu Hiệu Quả Render
Setting V-Ray 5 Cho 3ds Max: Hướng Dẫn Tối Ưu Hiệu Quả Render D5 Converter 3ds Max: Hướng Dẫn Chi Tiết Và Các Tính Năng Nổi Bật
D5 Converter 3ds Max: Hướng Dẫn Chi Tiết Và Các Tính Năng Nổi Bật Xóa Lịch Sử Chrome Trên Máy Tính: Hướng Dẫn Chi Tiết Và Hiệu Quả
Xóa Lịch Sử Chrome Trên Máy Tính: Hướng Dẫn Chi Tiết Và Hiệu Quả VLC Media Player Android: Hướng Dẫn Chi Tiết và Tính Năng Nổi Bật
VLC Media Player Android: Hướng Dẫn Chi Tiết và Tính Năng Nổi Bật Chuyển File Canva Sang AI: Hướng Dẫn Nhanh Chóng và Đơn Giản Cho Người Mới Bắt Đầu
Chuyển File Canva Sang AI: Hướng Dẫn Nhanh Chóng và Đơn Giản Cho Người Mới Bắt Đầu Chuyển từ Canva sang PowerPoint - Hướng dẫn chi tiết và hiệu quả
Chuyển từ Canva sang PowerPoint - Hướng dẫn chi tiết và hiệu quả Ghi Âm Zoom Trên Máy Tính: Hướng Dẫn Chi Tiết và Mẹo Hữu Ích
Ghi Âm Zoom Trên Máy Tính: Hướng Dẫn Chi Tiết và Mẹo Hữu Ích "Notion có tiếng Việt không?" - Hướng dẫn thiết lập và lợi ích khi sử dụng
"Notion có tiếng Việt không?" - Hướng dẫn thiết lập và lợi ích khi sử dụng Facebook No Ads XDA - Trải Nghiệm Không Quảng Cáo Đáng Thử
Facebook No Ads XDA - Trải Nghiệm Không Quảng Cáo Đáng Thử Autocad Alert: Giải Pháp Toàn Diện cho Mọi Thông Báo và Lỗi Thường Gặp
Autocad Alert: Giải Pháp Toàn Diện cho Mọi Thông Báo và Lỗi Thường Gặp Ký Hiệu Trên Bản Vẽ AutoCAD: Hướng Dẫn Toàn Diện và Thực Hành
Ký Hiệu Trên Bản Vẽ AutoCAD: Hướng Dẫn Toàn Diện và Thực Hành Tổng hợp lisp phục vụ bóc tách khối lượng xây dựng
Tổng hợp lisp phục vụ bóc tách khối lượng xây dựng Chỉnh kích thước số dim trong cad – cách đơn giản nhất 2024
Chỉnh kích thước số dim trong cad – cách đơn giản nhất 2024