Chủ đề anaconda yellowbrick: Anaconda Yellowbrick là bộ công cụ mạnh mẽ giúp trực quan hóa dữ liệu và mô hình trong Python. Bài viết này sẽ cung cấp hướng dẫn chi tiết về cách cài đặt, sử dụng và tối ưu hóa Yellowbrick với Anaconda, hỗ trợ người dùng trong các dự án học máy và khoa học dữ liệu. Cùng khám phá cách sử dụng hiệu quả để cải thiện hiệu suất công việc của bạn.
Mục lục
Anaconda và Yellowbrick: Giải pháp trực quan hóa và quản lý môi trường lập trình
Anaconda và Yellowbrick là hai công cụ phổ biến hỗ trợ các nhà khoa học dữ liệu, lập trình viên và nhà phân tích trong việc quản lý môi trường lập trình và trực quan hóa dữ liệu. Đây là những công cụ hữu ích cho việc tối ưu hóa quá trình phát triển và phân tích dữ liệu trong các dự án sử dụng Python.
Anaconda: Nền tảng quản lý môi trường lập trình Python
Anaconda là một nền tảng nguồn mở được sử dụng rộng rãi để quản lý môi trường lập trình Python và R. Anaconda giúp cài đặt và quản lý các gói phần mềm dễ dàng hơn, đồng thời cung cấp công cụ mạnh mẽ như Jupyter Notebook và Spyder để phát triển và kiểm thử mã lệnh.
- Anaconda bao gồm Conda, một trình quản lý gói mạnh mẽ hỗ trợ cài đặt và quản lý môi trường lập trình.
- Anaconda hỗ trợ hàng ngàn gói thư viện phục vụ cho khoa học dữ liệu, học máy và các lĩnh vực phân tích khác.
- Anaconda là giải pháp lý tưởng để quản lý môi trường ảo và tránh xung đột giữa các phiên bản của các gói phần mềm.
Yellowbrick: Thư viện trực quan hóa dữ liệu trong Machine Learning
Yellowbrick là một thư viện trực quan hóa dữ liệu được thiết kế để hỗ trợ các nhà khoa học dữ liệu trong việc phân tích và đánh giá mô hình học máy. Thư viện này giúp tạo ra các biểu đồ và đồ thị trực quan nhằm minh họa quá trình huấn luyện và kiểm thử các mô hình học máy.
- Yellowbrick tích hợp với Scikit-learn, một thư viện học máy phổ biến trong Python.
- Các trực quan hóa phổ biến bao gồm ma trận nhầm lẫn, biểu đồ ROC, biểu đồ phân tán, và biểu đồ trực quan hóa lỗi dự báo.
- Yellowbrick giúp phát hiện các vấn đề trong quá trình xây dựng mô hình, như tương quan giữa các biến hoặc vấn đề quá khớp.
Ứng dụng của Anaconda và Yellowbrick trong khoa học dữ liệu
Anaconda và Yellowbrick được sử dụng rộng rãi trong các dự án khoa học dữ liệu và học máy. Chúng giúp nhà khoa học dữ liệu không chỉ tập trung vào việc phát triển mô hình mà còn có thể trực quan hóa và kiểm thử các mô hình đó một cách dễ dàng và hiệu quả.
- Anaconda giúp tạo và quản lý môi trường lập trình với đầy đủ các gói cần thiết như NumPy, Pandas, Matplotlib và Scikit-learn.
- Yellowbrick cung cấp các công cụ trực quan giúp đánh giá mô hình thông qua các biểu đồ trực quan, hỗ trợ nhà khoa học dữ liệu dễ dàng xác định điểm mạnh và yếu của mô hình.
- Việc sử dụng kết hợp Anaconda và Yellowbrick trong các dự án khoa học dữ liệu giúp tăng hiệu suất làm việc và nâng cao chất lượng dự đoán của mô hình.
Ví dụ sử dụng Yellowbrick trong trực quan hóa dữ liệu
Dưới đây là một ví dụ về việc sử dụng thư viện Yellowbrick để trực quan hóa tương quan giữa các đặc tính dữ liệu trong mô hình học máy:
Mã lệnh trên sẽ tạo ra một biểu đồ thể hiện sự tương quan giữa các cặp đặc tính trong dữ liệu, giúp dễ dàng nhận diện mối quan hệ giữa các biến và từ đó tối ưu hóa mô hình học máy.
Kết luận
Anaconda và Yellowbrick là hai công cụ mạnh mẽ giúp tăng hiệu quả và chất lượng trong quá trình phát triển và trực quan hóa dữ liệu khoa học. Sự kết hợp giữa việc quản lý môi trường lập trình và công cụ trực quan hóa giúp tối ưu hóa quá trình xây dựng mô hình học máy, từ đó giúp nhà khoa học dữ liệu đưa ra các quyết định chính xác hơn.

.png)
Anaconda là gì?
Anaconda là một nền tảng quản lý môi trường và gói phần mềm mã nguồn mở, chủ yếu được sử dụng trong lĩnh vực khoa học dữ liệu và học máy. Anaconda cung cấp một môi trường phát triển mạnh mẽ để xây dựng và thử nghiệm các mô hình máy học, bao gồm việc quản lý các thư viện Python và các công cụ hỗ trợ liên quan. Nền tảng này rất phổ biến nhờ khả năng đơn giản hóa việc quản lý gói, môi trường ảo và hỗ trợ cả Python lẫn R.
Lợi ích của Anaconda
- Quản lý môi trường: Anaconda cho phép tạo và quản lý các môi trường ảo một cách dễ dàng, đảm bảo rằng mỗi dự án có thể sử dụng các phiên bản thư viện phù hợp mà không gây xung đột.
- Kho gói phong phú: Người dùng có thể truy cập vào hơn 7.500 gói dữ liệu khoa học, từ NumPy, Pandas, đến các công cụ học máy như TensorFlow và Scikit-learn.
- Tích hợp dễ dàng với Jupyter Notebook: Jupyter Notebook, một công cụ phổ biến để viết và chạy các mã Python, được tích hợp sẵn trong Anaconda, giúp người dùng dễ dàng thực hiện các bài phân tích và trực quan hóa dữ liệu.
- Tính tương thích cao: Anaconda tương thích với nhiều hệ điều hành khác nhau như Windows, macOS, và Linux, tạo điều kiện thuận lợi cho việc triển khai trên các hệ thống khác nhau.
Tại sao sử dụng Anaconda trong khoa học dữ liệu?
Anaconda được sử dụng rộng rãi trong lĩnh vực khoa học dữ liệu nhờ vào khả năng tích hợp nhiều công cụ hữu ích và sự dễ dàng trong việc quản lý các dự án lớn. Các lập trình viên và nhà khoa học dữ liệu thường lựa chọn Anaconda bởi khả năng:
- Thiết lập môi trường riêng biệt cho từng dự án mà không gặp phải vấn đề xung đột phiên bản thư viện.
- Dễ dàng cài đặt các gói cần thiết từ Anaconda hoặc Conda-forge, một kho gói mã nguồn mở lớn dành cho Anaconda.
- Hỗ trợ đầy đủ cho cả lập trình Python và R, hai ngôn ngữ phổ biến trong khoa học dữ liệu.
- Khả năng tích hợp các công cụ trực quan hóa dữ liệu như Yellowbrick để đánh giá và tối ưu hóa các mô hình học máy.
Anaconda và Yellowbrick
Yellowbrick là một thư viện trực quan hóa hỗ trợ xây dựng và đánh giá mô hình học máy, giúp người dùng dễ dàng hiểu và so sánh kết quả. Được tích hợp sẵn trong Anaconda, Yellowbrick mang lại nhiều lợi ích cho các nhà khoa học dữ liệu trong việc tối ưu hóa mô hình, như phân tích độ chính xác, độ lệch của mô hình và trực quan hóa quá trình huấn luyện mô hình.
Bắt đầu với Anaconda
| Bước 1 | Cài đặt Anaconda từ trang chủ chính thức của Anaconda. |
| Bước 2 | Tạo môi trường ảo bằng câu lệnh: conda create -n myenv python=3.8 |
| Bước 3 | Kích hoạt môi trường mới tạo bằng câu lệnh: conda activate myenv |
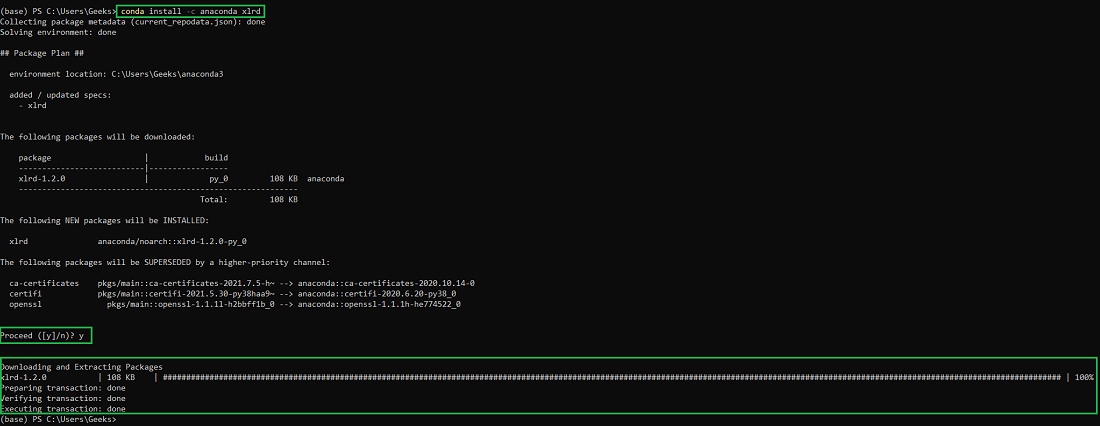
| Bước 4 | Cài đặt các gói cần thiết cho dự án như Yellowbrick: conda install -c conda-forge yellowbrick |
Với những bước trên, bạn có thể bắt đầu sử dụng Anaconda cho các dự án khoa học dữ liệu của mình một cách hiệu quả.
Yellowbrick: Công cụ trực quan hóa mô hình
Yellowbrick là một thư viện Python giúp trực quan hóa các mô hình học máy, hỗ trợ nhà khoa học dữ liệu phân tích và cải thiện hiệu suất của mô hình. Nó được xây dựng trên nền tảng của các thư viện phổ biến như matplotlib và scikit-learn, giúp dễ dàng tích hợp vào các dự án hiện tại. Yellowbrick cung cấp nhiều công cụ hữu ích để giúp người dùng hiểu rõ hơn về quá trình huấn luyện và dự đoán của mô hình.
Các tính năng chính của Yellowbrick
- Trực quan hóa quá trình huấn luyện mô hình và đánh giá độ chính xác.
- So sánh các thuật toán học máy khác nhau để tìm ra mô hình tốt nhất.
- Phân tích độ nhạy và tính chính xác của mô hình thông qua các biểu đồ dễ hiểu.
- Tích hợp trực tiếp với scikit-learn, cho phép tận dụng sức mạnh của các thuật toán học máy phổ biến.
Ưu điểm của việc sử dụng Yellowbrick
Yellowbrick không chỉ giúp trực quan hóa các mô hình mà còn cung cấp thông tin chi tiết về cách các thuật toán học máy hoạt động. Với các biểu đồ rõ ràng và minh bạch, người dùng có thể:
- Nhận diện những điểm mạnh và yếu của mô hình.
- So sánh trực quan giữa các mô hình khác nhau trên cùng một tập dữ liệu.
- Dễ dàng phát hiện các lỗi tiềm ẩn hoặc dữ liệu ngoại lệ trong quá trình huấn luyện.
Các bước cài đặt Yellowbrick
| Bước 1 | Cài đặt Yellowbrick thông qua Anaconda bằng câu lệnh: conda install -c conda-forge yellowbrick |
| Bước 2 | Tích hợp vào mô hình học máy bằng cách sử dụng các biểu đồ như ClassificationReport hoặc ROC AUC để đánh giá mô hình. |
| Bước 3 | Sử dụng các biểu đồ trực quan như ResidualsPlot để phân tích hiệu suất của mô hình dự đoán. |
Ứng dụng của Yellowbrick trong khoa học dữ liệu
Yellowbrick thường được sử dụng để trực quan hóa quá trình huấn luyện mô hình học máy. Ví dụ, với các bài toán phân loại, người dùng có thể sử dụng biểu đồ phân loại để phân tích độ chính xác của mô hình theo các lớp khác nhau. Đối với các bài toán hồi quy, các biểu đồ dư thừa có thể giúp hiểu rõ hơn về sự phân phối của lỗi dự đoán.

Sử dụng Yellowbrick với Anaconda
Yellowbrick là một công cụ hữu ích cho việc trực quan hóa mô hình học máy trong Python. Khi kết hợp với Anaconda, quá trình cài đặt và sử dụng Yellowbrick trở nên đơn giản và hiệu quả. Bên dưới là hướng dẫn từng bước để cài đặt và sử dụng Yellowbrick với Anaconda.
Các bước cài đặt Yellowbrick bằng Anaconda
- Cài đặt Anaconda: Trước tiên, bạn cần cài đặt Anaconda, một môi trường quản lý Python phổ biến. Tải xuống và cài đặt Anaconda từ trang chủ Anaconda.
- Tạo môi trường ảo: Sử dụng Anaconda để tạo một môi trường ảo mới cho dự án của bạn. Điều này giúp bạn cô lập các thư viện cần thiết. Chạy lệnh sau trong Anaconda Prompt: \[ conda create -n myenv python=3.8 \] Sau đó, kích hoạt môi trường: \[ conda activate myenv \]
- Cài đặt Yellowbrick: Sau khi môi trường ảo đã được kích hoạt, bạn có thể cài đặt Yellowbrick bằng lệnh sau: \[ conda install -c conda-forge yellowbrick \]
Sử dụng Yellowbrick trong dự án
Sau khi cài đặt Yellowbrick, bạn có thể sử dụng nó trong các dự án học máy để trực quan hóa các mô hình. Dưới đây là một ví dụ về cách sử dụng Yellowbrick để tạo biểu đồ đánh giá mô hình phân loại:
from yellowbrick.classifier import ClassificationReport
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
# Tải dữ liệu và chia tập dữ liệu
data = load_iris()
X_train, X_test, y_train, y_test = train_test_split(data.data, data.target, test_size=0.2)
# Tạo mô hình học máy
model = RandomForestClassifier()
# Huấn luyện mô hình
model.fit(X_train, y_train)
# Trực quan hóa kết quả với Yellowbrick
visualizer = ClassificationReport(model, classes=data.target_names)
visualizer.score(X_test, y_test)
visualizer.show()Ưu điểm của việc sử dụng Yellowbrick với Anaconda
- Anaconda cung cấp môi trường quản lý các thư viện một cách dễ dàng và ổn định.
- Yellowbrick giúp bạn trực quan hóa hiệu suất mô hình một cách rõ ràng và nhanh chóng.
- Cả hai công cụ này đều miễn phí và dễ cài đặt, phù hợp với cả người mới bắt đầu và chuyên gia.
Các công cụ hỗ trợ trong Anaconda
Anaconda là một nền tảng mạnh mẽ dành cho các nhà khoa học dữ liệu và lập trình viên, hỗ trợ việc phát triển và triển khai các ứng dụng khoa học dữ liệu. Dưới đây là một số công cụ hỗ trợ hữu ích trong Anaconda:
- Yellowbrick: Đây là một thư viện trực quan hóa máy học trong Python. Yellowbrick giúp các nhà phát triển tạo ra những biểu đồ trực quan để hiểu rõ hơn về cách hoạt động của các mô hình máy học. Ví dụ, với
yellowbrick.text.FreqDistVisualizer, người dùng có thể dễ dàng hình dung tần suất xuất hiện của các từ trong văn bản. - Spyder: Một IDE (Integrated Development Environment) được tối ưu hóa cho Python, tích hợp sẵn trong Anaconda. Spyder có giao diện thân thiện với nhiều tính năng hỗ trợ lập trình và phân tích dữ liệu.
- Jupyter Notebook: Là một công cụ phổ biến cho việc phát triển và chia sẻ mã nguồn Python trong Anaconda. Jupyter cho phép viết mã nguồn kèm theo kết quả và giải thích ngay trong cùng một môi trường, thuận tiện cho việc ghi chép và chia sẻ.
- NumPy và Pandas: Đây là hai thư viện quan trọng trong việc xử lý dữ liệu lớn. NumPy cung cấp các hàm toán học hiệu quả, còn Pandas giúp xử lý và phân tích dữ liệu dạng bảng.
- Matplotlib: Là một thư viện mạnh mẽ cho việc tạo các đồ thị và biểu đồ trong Python. Kết hợp với Yellowbrick, Matplotlib giúp trực quan hóa các kết quả phân tích dữ liệu một cách dễ dàng và sinh động.
Một số công cụ khác như TensorFlow, Keras, và Scikit-learn cũng được hỗ trợ trong Anaconda, giúp tối ưu hóa các tác vụ học máy và phân tích dữ liệu. Những công cụ này đều được thiết kế để làm việc dễ dàng với Python và được cài đặt sẵn qua Anaconda Navigator hoặc dòng lệnh conda.
Ví dụ về sử dụng Yellowbrick
from yellowbrick.text import FreqDistVisualizer
from sklearn.feature_extraction.text import CountVectorizer
# Mở tệp văn bản và xử lý
corpus = open('text.txt', 'r')
vectorizer = CountVectorizer()
docs = vectorizer.fit_transform(corpus)
features = vectorizer.get_feature_names()
# Trực quan hóa tần suất từ
visualizer = FreqDistVisualizer(features=features, orient='v')
visualizer.fit(docs)
visualizer.show()
Trong ví dụ này, FreqDistVisualizer từ Yellowbrick được sử dụng để hiển thị tần suất các từ xuất hiện trong một tệp văn bản. Điều này rất hữu ích khi cần trực quan hóa dữ liệu văn bản.
















 Blender Room - Cách Tạo Không Gian 3D Tuyệt Đẹp Bằng Blender
Blender Room - Cách Tạo Không Gian 3D Tuyệt Đẹp Bằng Blender Setting V-Ray 5 Cho 3ds Max: Hướng Dẫn Tối Ưu Hiệu Quả Render
Setting V-Ray 5 Cho 3ds Max: Hướng Dẫn Tối Ưu Hiệu Quả Render D5 Converter 3ds Max: Hướng Dẫn Chi Tiết Và Các Tính Năng Nổi Bật
D5 Converter 3ds Max: Hướng Dẫn Chi Tiết Và Các Tính Năng Nổi Bật Xóa Lịch Sử Chrome Trên Máy Tính: Hướng Dẫn Chi Tiết Và Hiệu Quả
Xóa Lịch Sử Chrome Trên Máy Tính: Hướng Dẫn Chi Tiết Và Hiệu Quả VLC Media Player Android: Hướng Dẫn Chi Tiết và Tính Năng Nổi Bật
VLC Media Player Android: Hướng Dẫn Chi Tiết và Tính Năng Nổi Bật Chuyển File Canva Sang AI: Hướng Dẫn Nhanh Chóng và Đơn Giản Cho Người Mới Bắt Đầu
Chuyển File Canva Sang AI: Hướng Dẫn Nhanh Chóng và Đơn Giản Cho Người Mới Bắt Đầu Chuyển từ Canva sang PowerPoint - Hướng dẫn chi tiết và hiệu quả
Chuyển từ Canva sang PowerPoint - Hướng dẫn chi tiết và hiệu quả Ghi Âm Zoom Trên Máy Tính: Hướng Dẫn Chi Tiết và Mẹo Hữu Ích
Ghi Âm Zoom Trên Máy Tính: Hướng Dẫn Chi Tiết và Mẹo Hữu Ích "Notion có tiếng Việt không?" - Hướng dẫn thiết lập và lợi ích khi sử dụng
"Notion có tiếng Việt không?" - Hướng dẫn thiết lập và lợi ích khi sử dụng Facebook No Ads XDA - Trải Nghiệm Không Quảng Cáo Đáng Thử
Facebook No Ads XDA - Trải Nghiệm Không Quảng Cáo Đáng Thử Autocad Alert: Giải Pháp Toàn Diện cho Mọi Thông Báo và Lỗi Thường Gặp
Autocad Alert: Giải Pháp Toàn Diện cho Mọi Thông Báo và Lỗi Thường Gặp Ký Hiệu Trên Bản Vẽ AutoCAD: Hướng Dẫn Toàn Diện và Thực Hành
Ký Hiệu Trên Bản Vẽ AutoCAD: Hướng Dẫn Toàn Diện và Thực Hành Tổng hợp lisp phục vụ bóc tách khối lượng xây dựng
Tổng hợp lisp phục vụ bóc tách khối lượng xây dựng Chỉnh kích thước số dim trong cad – cách đơn giản nhất 2024
Chỉnh kích thước số dim trong cad – cách đơn giản nhất 2024